
Posted by Laura Sangha
9 April 2024Harry Smith
In this blog post, Research Fellow Harry Smith provides an overview of some of the innovative digital methods used by our project. Read on to find out more about the digitisation of manuscript sources, and how Artificial Intelligence (AI) and automatic transcription can be used to improve access to handwritten documents such as wills.
Previous entries in this blog have, so far, focused on the value of wills as historical sources, demonstrating the substantial range of topics that the contents of wills can help us understand. The value of wills has long been known, and plenty of historians have used them to examine inheritance, changing religious beliefs, family structure and other topics, but all this work has been based on small samples of wills because they take a substantial amount of time to process by hand. Wills in our period (c.1540-1790) take perhaps half an hour to an hour to transcribe. This has placed a limit on the size of previous projects based on the evidence included in wills. In contrast, our project will use a far larger sample of wills (25,000) and this blog briefly details how we will be able to transcribe this number of documents, and the problems we are likely to encounter.
Automatic Transcription
Our approach uses a combination of automatic transcription, expert volunteers and crowd sourcing to process wills quickly. Automatic transcription of historical sources has been undertaken by various organisations for some time. Some such projects have been led by historians and other academics, such as the Old Bailey Online, but many have been undertaken by commercial bodies, such as the corpus of text underlying Google Books. In the case of printed text, Optical Character Recognition (OCR) systems have been used to great effect by various bodies to generate reasonably accurate transcriptions of large quantities of material.
Handwritten text, however, is considerably harder to deal with. Whereas printed texts are fairly consistent in the shape and spacing of characters, handwriting contains enormous variation on both counts. Consequently, Handwritten Text Recognition (HTR) models have taken longer to develop. This has had considerable impact on historical scholarship, particularly in the early modern period where printed text has an outsized importance in the evidence base used by recent scholars, because printed texts have been digitised in far greater numbers than manuscript, handwritten material, through projects such as Early English Books Online. This has had a distorting effect on the focus of recent scholarship on this period with substantial implications for our understanding of the sixteenth to eighteenth centuries because the printed word is far easier to access at scale presently than manuscript sources, such as wills.
Transkribus
In recent years, however, HTR models have developed substantially, and the platform Transkribus, developed by the READ-Coop, is being used more and more frequently to process handwritten material from different time periods and different countries. It is this tool which will allow us to transcribe 25,000 wills within the timeframe of this project. There is an ever-expanding literature on the topic of text recognition in general, and Transkribus in particular, so here I will just summarise the general principles and detail how our project will use the platform.
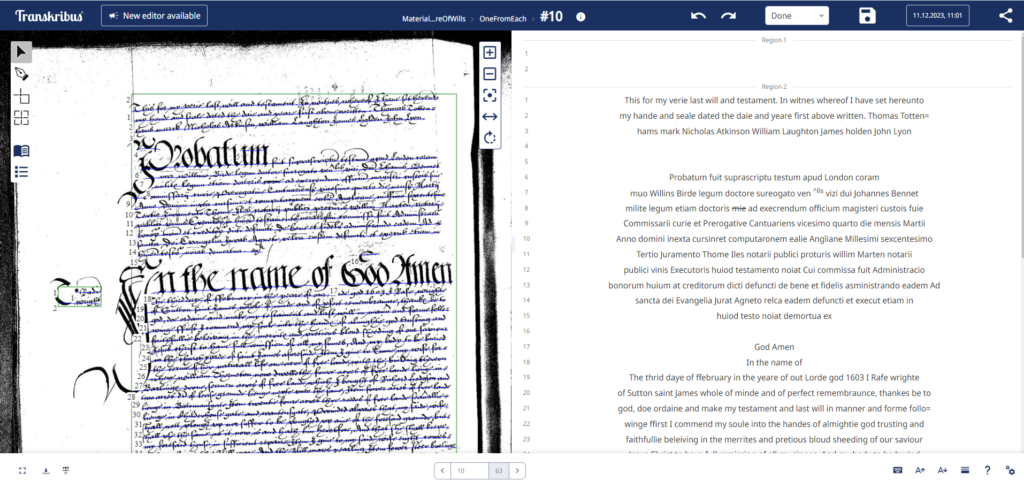
There are a wide range of HTR models available through Transkribus, and the platform also allows users to create their own models. In each case, however, the process underlying them is the same. First, a set of ground truth transcriptions are required. These are full transcriptions of images containing the handwriting that a user will require the model to read. This ground truth is split into two sections, a training set and a validation set. The images and transcriptions from the training set are used to teach the model the given handwriting style. The model is then tested on the validation set, it is fed the images, and the output from the model is checked against the transcription, to calculate the Character Error Rate (CER) – the percentage of characters which the model has misidentified. Assuming this error rate is acceptable to the user, the model can then be run on the documents they want to digitise. If the error rate is too high, then additional training can be undertaken by providing more example transcriptions and images.
Our wills dataset
In our project we are lucky to have a set of expert volunteers who are at present transcribing over 400 pages from wills which will form our ground truth data. This sample is drawn from across our timeframe because of the considerable variation in handwriting between each sample period (1538-52, 1604-08, 1664-6, 1725-6 and 1785-6). This method will provide a corpus of expert transcriptions which will allow us to train at least one model to transcribe our wills. This will be an iterative process, and we may find that we need a model for each century or even each period, depending on how well it can cope with the different styles of handwriting.
Once the model is trained, we will then use it on the 25,000 wills proved in our sample periods; this will produce a considerable amount of automatically generated text. On average a will is perhaps one or two pages in this period, and each page contains around 50 lines of text. Therefore, we will end up with perhaps two million lines of text. How we check and process this volume of text is a considerable problem.
First of all, it is a logistical problem, two million lines of text is too many for us to be able to check by hand as a team. We need, therefore, to use some kind of automatic checking based on a language model which allows us, for example, to evaluate what proportion of a given line is in English. A second set of automatic checks will take advantage of the formulaic nature of wills; the objects, places and people mentioned in a will change, but the structure of the will and kind of phrasing used remained stable. Both kinds of checks can be done in Python using modules such as ‘re’ which allows us to use regular expressions to identify recurring patterns of words in text, or we can adapt a machine learning module inb Python, such as spacy, to help check the language and find patterns within the lines of text.
Neither of these approaches is perfect, however, and we will need to check a sample of the HTR output by hand. In order to do this we will be using the Zooniverse platform. Zooniverse is a citizen science platform where millions of volunteers contribute to a wide range of projects in the sciences, social sciences and humanities. A future blog will describe this part of the project, but simply put Zooniverse will allow us to check all the lines of text which contain mention of objects or people – the two parts of wills which particularly interest our project given the insights into material culture which they provide. Not every line of text will mention an object or individual, so we will only have to use Zooniverse to check a fraction of the total output from the HTR model.
How accurate is accurate enough?
If we have ways of overcoming the logistics of checking two million or more lines of text, then the second problem is far more difficult to resolve; how accurate is accurate enough? We could spend the entirety of our project checking model outputs, using those checks to refine the model, checking the new outputs and so on, attempting to capture exactly what was written on the page. However, we would then not be able to undertake any analysis, and it is likely that even the four years of this project would still not be enough to produce an entirely accurate transcription of 25,000 wills, capturing every variant spelling and deciphering every faded word. In large part this is because, even with hand checking the 100,000s of lines which mention an object or person, for the majority of lines neither the project team nor a volunteer will be consulting the original image. Thus, in cases where a word is misspelt, we will not know if that is a variant spelling in the original text, or if the model has introduced an error.
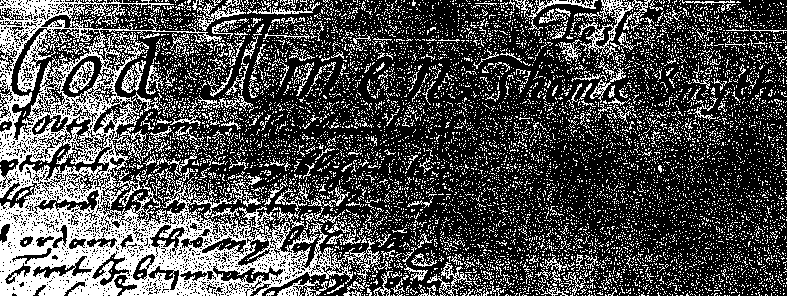
What will ultimately determine when we stop refining the transcription is our purpose in digitising these wills. Our project is concerned with material culture, and the transcriptions we produce will be accurate as possible in terms of the goods mentioned and the context that surrounds those goods. The transcriptions will not, however, be perfect in all regards, instead they will provide a starting point for other users to develop them further, using the tools and approach we have provided. This reminds us all as consumers of digitised texts that the purpose and background of any digitisation project will determine the nature of the output. Even a project aiming at perfect transcriptions will be constrained by the resources available and the conventions adopted.
Tim Hitchcock, ‘Confronting the Digital or How Academic History Writing Lost the Plot’, Cultural and Social History, 10/1 (2013), pp. 9-23, https://doi.org/10.2752/147800413X13515292098070
Joe Nockels, Paul Gooding, Sarah Ames and Melissa Terras, ‘Understanding the application of handwritten text recognition technology in heritage contexts: a systematic review of Transkribus in published research’, Archival Science, 22 (2022), pp. 367-92, https://doi.org/10.1007/s10502-022-09397-0
Joan Andreu Sánchez, Verónica Romero, Alejandro H. Toselli, Mauricio Villegas andEnrique Vidal, ‘A set of benchmarks for Handwritten Text Recognition on historical documents’, Pattern Recognition, 94 (2019), pp. 122-34, https://doi.org/10.1016/j.patcog.2019.05.025