

Posted by Edward Mills
17 April 2020Just over two months ago, we announced the start of a new project based at the Centre for Medieval Studies here in Exeter: Learning French in Medieval England. Our aim is to produce a digital edition of Walter de Bibbesworth’s Tretiz, a rhymed French vocabulary of the mid-thirteenth century that has attracted significant critical interest for its insight into multilingual medieval England. Today, we’d like to take a few minutes to bring you up to date on what we’ve been up to since then, and offer a few hints as to where we might be heading in the near future.
Of course, it’s been a busy couple of months in the wider world as a whole, and the Covid-19 situation has, as you’d expect, had a knock-on effect on our project. In particular, the cancellation of the 2020 International Congress on Medieval Studies, where Edward Mills was looking forward to presenting on the project, has been very disappointing — although we are all of course in complete agreement with the decision reached by the committee. On a day-to-day level, we’ve shared the experience of researchers around the world in suddenly adapting to working from home, a task that has (in our case) been made far easier by the incredible work of the IT team here in Exeter. We’re very grateful to them for everything that they’ve done at very short notice, from bringing forward the roll-out of a new VPN to opening up access to Microsoft Teams; without their tireless work over the last month, our project (and much of medieval studies in Exeter more broadly) would have struggled to continue working during this uncertain period.
It’s thanks to support from colleagues, both within and outside of the medieval studies community, that we’re able to bring you up to date on some exciting developments in the project over the past few months. Since our initial blog post a couple of months ago, our work has been focused on transcribing the manuscripts of the Tretiz, many of which have (thankfully) been digitised by libraries in the UK and abroad. Transcription is the first step in our editing process, and aims to produce an accurate representation of what’s on the manuscript page before we start making editorial decisions: at this stage, that means we’re expanding abbreviations and recording anything that strikes us as particularly noteworthy, but not normalising letters such as ‘u’ / ‘v’ or ‘i’ / ‘j’ (two pairs which are often used differently in medieval manuscripts to how they are today). We’re also preserving the original word-spacing found within each manuscript, which can be a slightly counter-intuitive experience; it does, however, provide some valuable insights into the attitudes and decisions of our individual scribes.
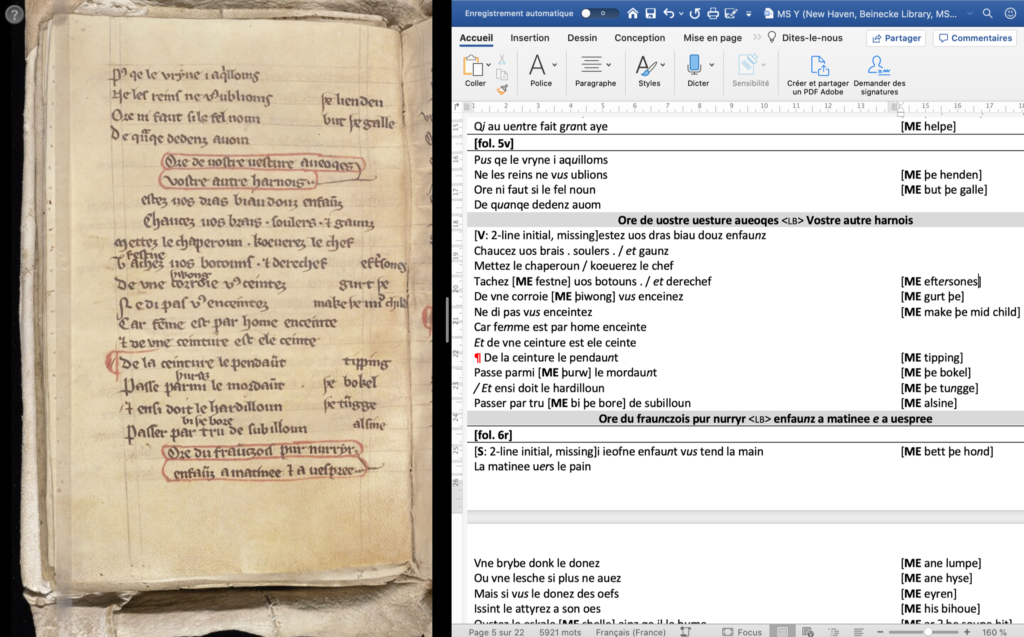
As you can see, we’re transcribing in Microsoft Word. This might seem like an odd decision: why not transcribe straight into an XML editor such as oXygen, which is where we’ll soon start encoding? There are three good reasons for this. The first is a practical one: specifically, it gives us a shallower learning curve at the outset. We’re all already familiar with editing documents in Microsoft Word, and can do so instantly with very quick results — putting ‘ME’ to mark glosses in bold, marking difficult-to-read characters in red, and so on — which means that, at this early stage, trends and patterns across different manuscripts are far easier to see in Word documents than they would be in XML. The second reason is rather more subtle: under the hood, XML and Word documents aren’t all that different. That little ‘x’ at the end the filename in the picture above stands for ‘XML’, as since 2003, all Microsoft Office applications have used XML ‘under-the-hood’ (see Microsoft’s own summary for a useful little overview). In effect, this means that we can produce our transcriptions in Word, before then exporting them into XML and marking them up in oXygen. As long as we’re consistent in our formatting, a simple find-and-replace should allow us to preserve most, if not all, of our annotations.
The main rationale behind our decision to use Word at this early stage, though, is one of time. While we start transcribing the manuscripts and indicating what features we’d like to encode, the team in Digital Humanities can observe our decisions, take on board our project’s aims, and get to work on deciding how to represent them in our final XML files. For instance, should we make a point of identifying abbreviations in different Tretiz manuscripts, and if so, how should we represent them? These are questions that it will take time to answer, and by getting underway with our transcription in as low-maintenance a way as possible, we can allow these conversations between the different members of the team to continue for longer, giving rise to more — and better — solutions in the process. As things stand, we’ve fully transcribed four manuscripts of the Tretiz, with several more underway, so there’s plenty to keep us occupied.
Aside from our manuscript transcription, we’ve also started work on how the project’s website will look. Since this is where we’ll be hosting our edition, it’s important for us to get this right, and so at this stage we’re focused on producing ‘wireframes’. A wireframe is essentially a mock-up (in our case, hand-drawn) of what the site could look like, which a developer will then take and transform into a working web page. Not everything that starts life on paper will eventually make it to the website, of course, but working on design at this stage will give us a useful sense of what’s possible (and, within the project’s limited time-frame, realistic) once the site goes live.
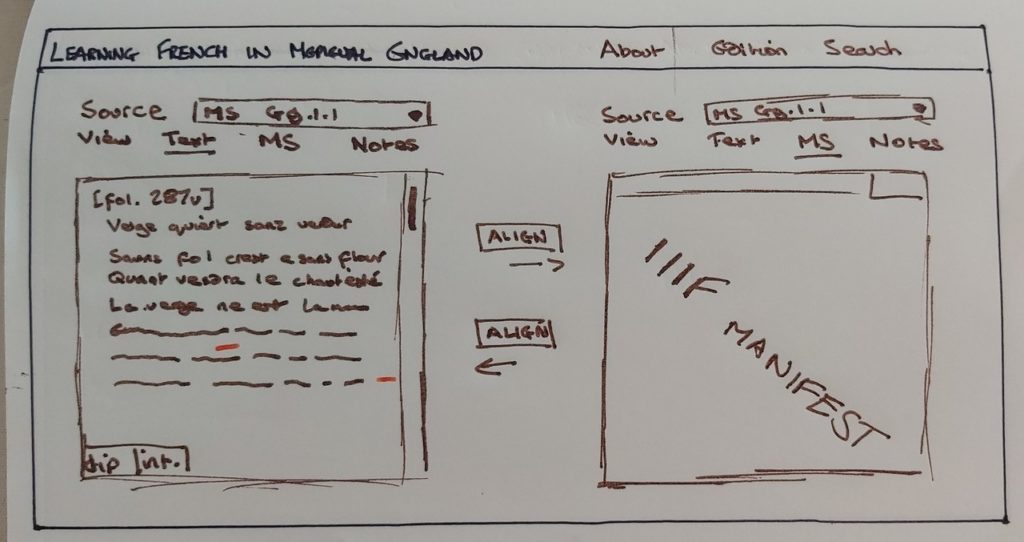
As you can see, our latest design — sketched very roughly, and not at all indicative of what might actually be possible — is very much centred around allowing users to choose how they interact with the text, its manuscript traditions, and our critical notes, in whatever combination they choose. We’re always keen to hear from readers who are interested in using our forthcoming edition of the Tretiz, so please do get in contact if you have any thoughts on our design, or any requests for what you’d like to be able to do with the Tretiz once it launches. Remember to follow us on Twitter @medievalfrench for all the latest project updates, as well as a weekly close look at particular aspects of the text itself on #TretizTuesday. We’ve also just launched our project website, which we warmly invite you to explore if you’re keen to learn more about both the Tretiz and the project itself.
We hope that this latest update has given you a sense of how the project’s progressing, as well as providing some degree of entertainment for all our readers who are stuck inside. We’ll be back in a couple of months’ time with another post, when we’ll be shining a light on some of the more specific challenges of transcription.
Tom Hinton and Edward Mills
Learning French in Medieval England project